Data Collection by Web Crawling
Hate Speech Detection
Date: 2023.07.27 ~ 2023.07.30
Writer: 9tailwolf
Introduction
The goal of my research is to determine what kind of hate occurs at what age and gender. So I need sentences data in the community that can represent each age group.
How to Choose Community
Trend Searching was used to identify communities that well represent the characteristics of each age group. Blackkiwi is a most useful site for searching Korean searching trends.
The target age/gender group of communities that I want to collect is 2030s male, 3040s male, 4050s male, 2030s female, 3040s female, 4050s female.
As a result I could select 6 communities.
- 81.8% of 2030s, 88.1% of male : FMkorea
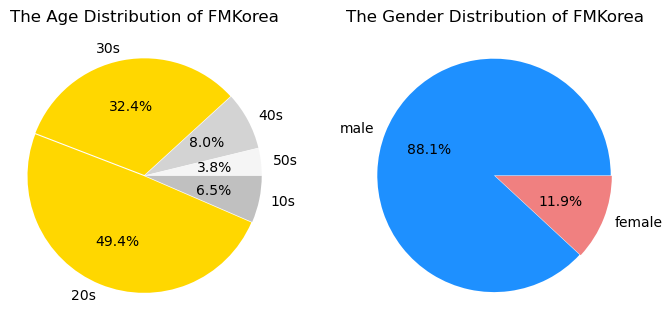
- 78.1% of 3040s, 93.5% of male : Ruliweb
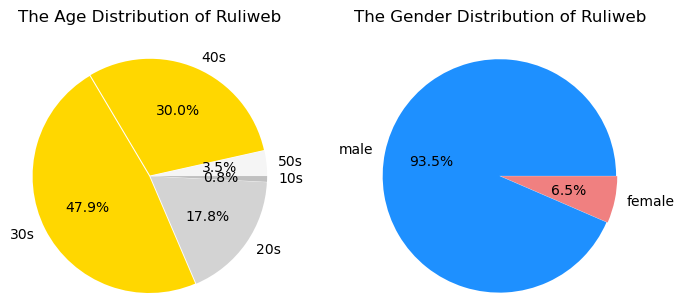
- 69.0% of 4050s, 65.9% of male : Clien
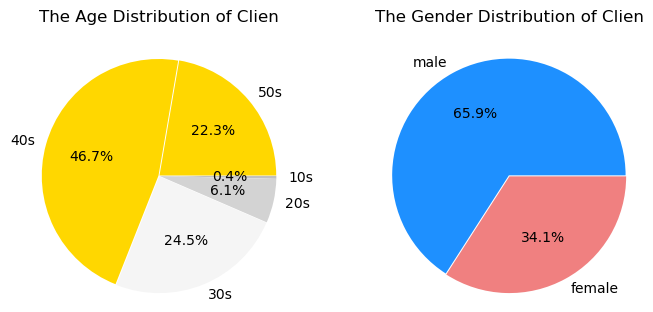
- 73.8% of 2030s, 95.0% of female : Theqoo
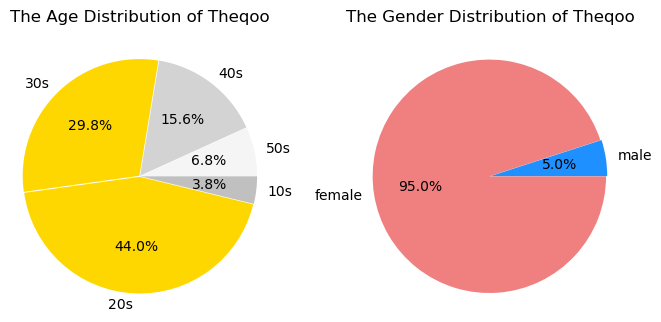
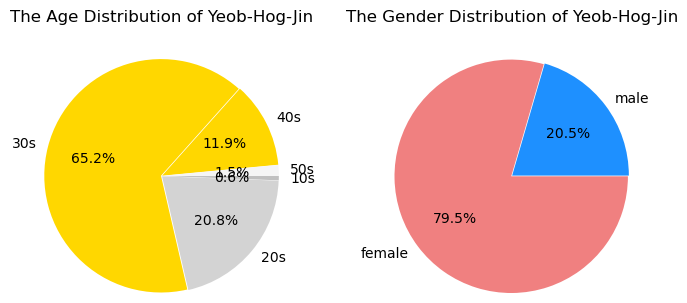
- 77.2% of 3040s, 79.5% of female : Yeobgi-Hogeun-Jinsil
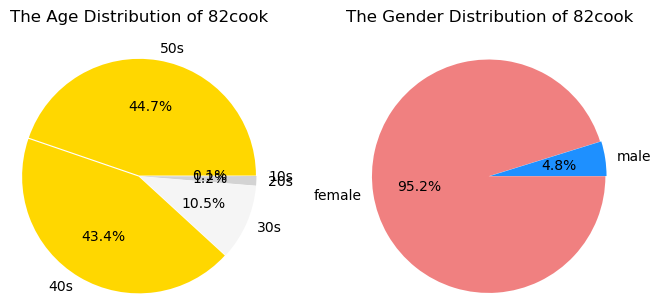
- 88.1% of 4050s, 95.2% of female : 82cook
Web Crawling for Collect Data
BeautifulSoap4 is a useful package tool library for parsing HTML and XML documents. By this, datas can be made a form of tree and it can be searched by python iteration. Selenium is also a useful package tool library for browser automation. This allows you to quickly and automatically browse the websight.
Below is a source code for using BeautifulSoap4 and Selenium.
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome() # Open Chrome
driver.implicitly_wait(10) # This code is for wating until the web is running.If you want to use Chrome for crawling, Chromedriver is essantial.
After that, it depends on the need and the website.
For example, to get data in Yeobgi-Hogeun-Jinsil, I run below code.
data = []
i = 3
while len(data)<5000: # Get 5,000 sentences data
html = driver.page_source # Getting html in html variable
soup = BeautifulSoup(html, 'html.parser') # Making Tree with BeautifulSoup
driver.implicitly_wait(10)
'''
The procedure of finging data
'''
a = soup.find('div',class_='cafe_group cafe_all').find_all('li',class_='thumbnail_on cmt_on')
for j in a[1:]:
data.append(j.find('span',class_='txt_detail').get_text())
'''
Turn the page
'''
if i!=7:
driver.find_element('xpath', '//*[@id="pagingNav"]/span['+str(i)+']').click()
else:
driver.find_element('xpath', '//*[@id="mArticle"]/div[2]/a[2]/span').click()
i = 2
i += 1
driver.implicitly_wait(10)In this way, I can collect 5,000 sentence datas with 6 selected communities.